IDK: Neural networks that say “I don’t know” to learn better
I teach the introductory atmospheric dynamics course for our masters students. A few years ago I noticed that the incoming students had perfected the art of partial credit – finding ways to get as many points as possible on exams without actually knowing the answers. While this may have led to a better final grade, it sort of missed the point. Furthermore, a critical skill for any scientist is to “know when they know and know when they don’t know”, and this class seemed like a great opportunity to try and get this message across.
A critical skill for any scientist is to know when they know and know when they don’t know
Because of this, the past few years I have implemented a new grading system on exams, where partial credit is no more, but students are allowed to write “IDK” (I don’t know) on any question and turn their solution in 24 hours later for half credit. The idea is to make them pause and assess whether they actually know the material or not.
An unexpected outcome of this grading exercise was that it made me reconsider how I use artificial neural networks (ANNs) in my scientific research. Why do I value scientists knowing when they don’t know, but turn around and train an ANN to provide an answer for everything all of the time? Put another way, I would prefer an ANN say “IDK” rather than get it horrendously wrong.
The concept of ANN confidence is nothing new, and in fact, uncertainty quantification for ANNs (both of the inputs and outputs) has become a very hot topic as of late. Furthermore, ANNs designed for classification tasks, to a certain extent, already output confidence via their softmax scoring. So, what’s the novel thing here?
Well, in many situations, we would never expect – in fact, it may be impossible – to get the answer right all of the time. Instead, we must look for particular states of the system that are more predictable than others (i.e. windows of opportunity; see Mariotti et al. 2019 for applications to weather prediction), and do our best to learn from and exploit these periods of predictability when they occur. By training ANNs to provide an answer for every prediction, it is likely that they are wasting energy trying to learn samples that may not be predictable in the first place.
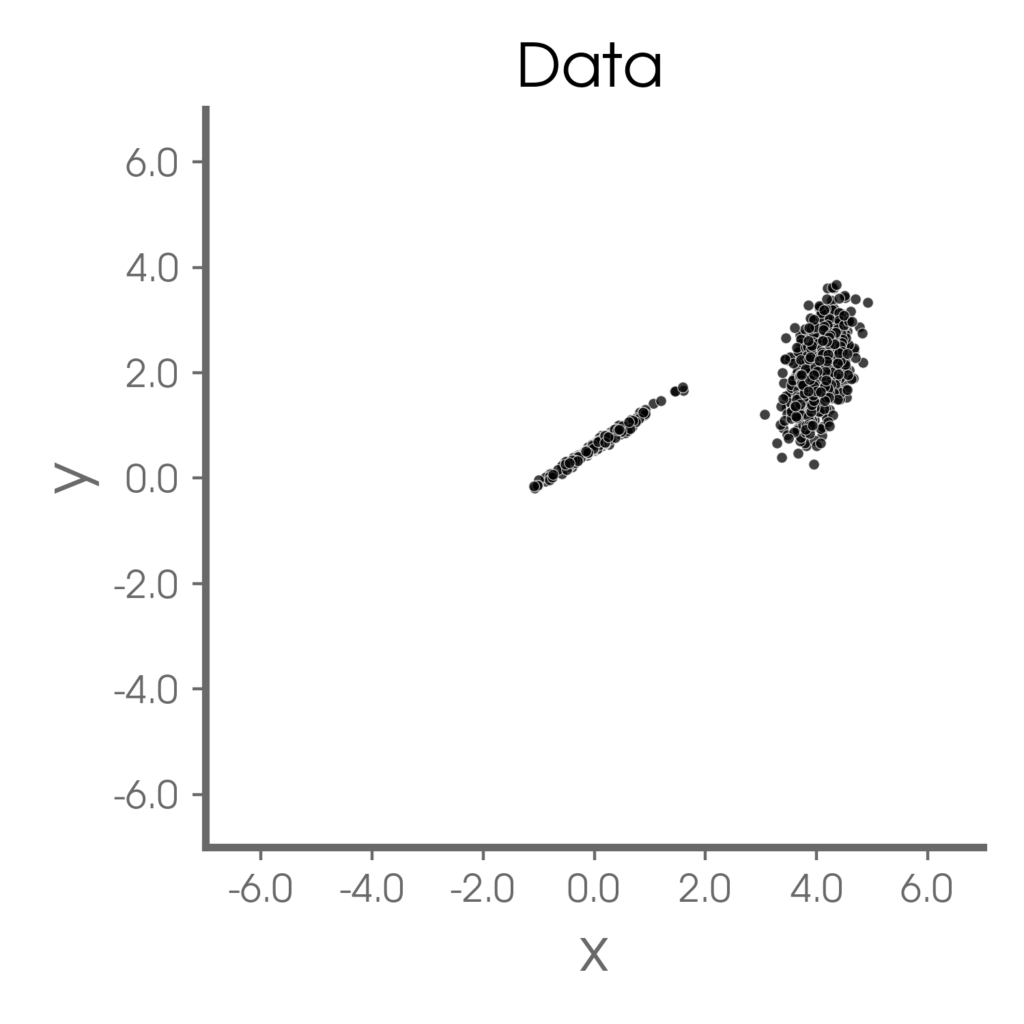
Take the simple 1D example in the figure to the right. Naively fitting a straight line through all of this data would result in a fit that performs poorly on most samples. Instead, I want an ANN that can learn to predict the samples along the line with high accuracy and also identify the samples within the point-cloud as being highly unpredictable (say “IDK”). That is, I want an ANN that can say “IDK” while it is training.
Motivated by this, the past few months my collaborator Dr. Randal Barnes (yes, there’s a relation…he’s my dad) and I explored ANN loss functions for regression and classification tasks, which we have termed Controlled Abstention Networks (CAN). The CAN identifies and learns from the more confident samples and abstains (says “IDK”) on the less confident samples during training. Our work leans heavily on that by Thulasidasan et al. (2019) and Thulasidasan (2020) which first introduced us to the concept of a simple classification loss function for abstention. What we’ve found is that when the network is able to abstain during training, it learns the predictable relationships better.
…when the network is able to abstain during training, it learns the predictable relationships better.
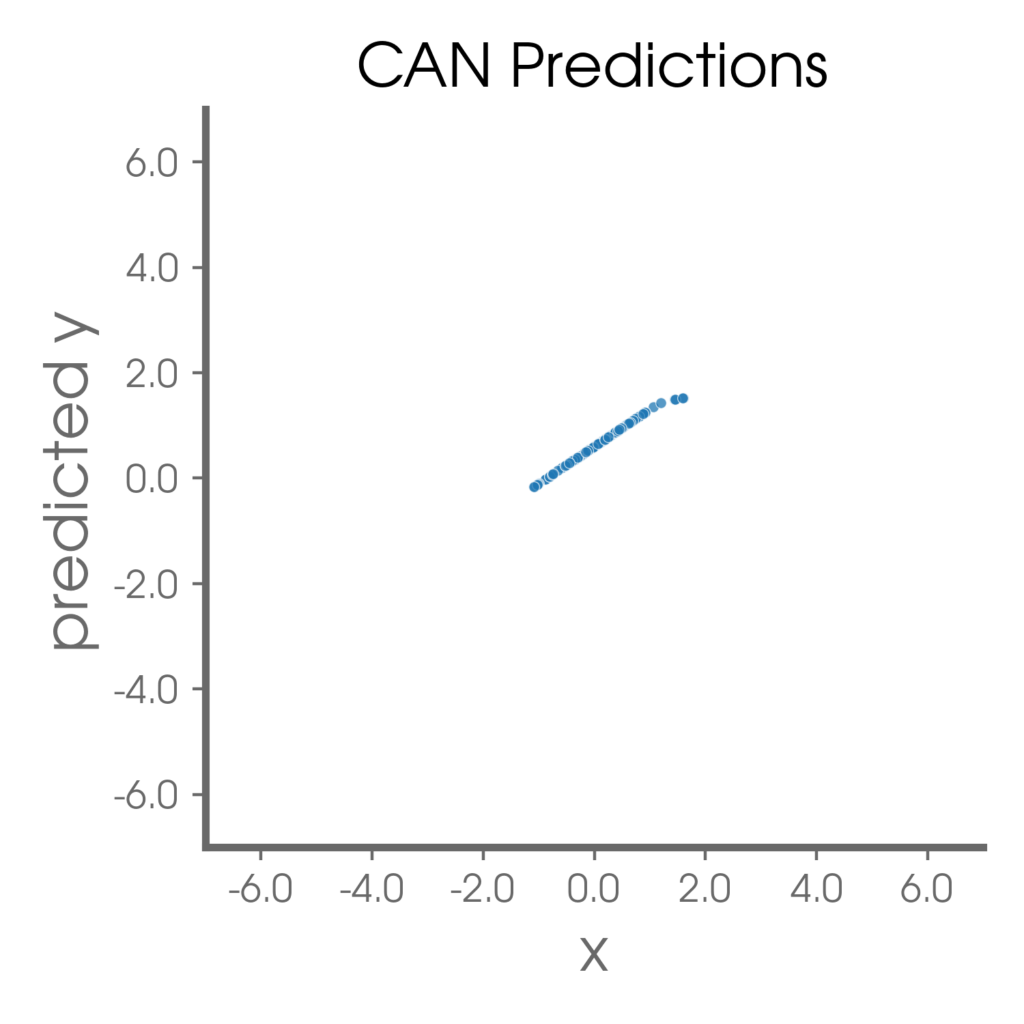
Returning to our 1D example, the CAN is able to identify, and learn from, the samples that fall along the well-defined line. Furthermore, the CAN learns to abstain on the samples within the point-cloud. Certainly this example is incredibly simplistic, but in our papers, we go beyond this 1D example and demonstrate the utility of the CAN for multiple complex climate use cases.
What gets me most excited about the CAN concept is that it spans a wide range of applications. We have found it useful for discovering particular input states that lead to predictable behaviour, identifying labels/outputs that are more predictable than others, or even acting as a data cleaner (i.e. filtering out noisy samples) during training to learn the non-noisy samples better.
I don’t ever expect to be able to predict the dynamics of the climate system perfectly – chaos theory sort of put that one to bed. Instead, abstention during training can help me search the data for predictable relationships, accommodating “IDK” along the way. That’s a good thing, as I doubt the Earth system gives partial credit.
References for the CAN
- Barnes, Elizabeth A. and Randal J. Barnes (2021a): Controlled abstention neural networks for identifying skillful predictions for classification problems, submitted to JAMES, 04/2021, preprint available at https://arxiv.org/abs/2104.08281.
- Barnes, Elizabeth A. and Randal J. Barnes (2021b): Controlled abstention neural networks for identifying skillful predictions for regression problems, submitted to JAMES, 04/2021, preprint available at https://arxiv.org/abs/2104.08236.
Fundamental references for this work
- Thulasidasan, S., T. Bhattacharya, J. Bilmes, G. Chennupati, and J. Mohd-Yusof, 2019: Combating Label Noise in Deep Learning Using Abstention. https://arxiv.org/abs/1905.10964.
- Thulasidasan, S., 2020: Deep Learning with abstention: Algorithms for robust training and predictive uncertainty. https://digital.lib.washington.edu/researchworks/handle/1773/45781.
The quest for reliably stable ML emulators of sub-grid convection for climate models – CLIVAR
[…] some desired properties on a coupled integration’s stability. Maybe Elizabeth Barnes’ latest “IDK” network architectures could allow for an NN emulator to infrequently opt out when things are too uncertain to make a […]
mspritch
This is really interesting Libby. I am curious to know if it would put any dent in our prognostic stability problems when using NN to emulate explicit subgrid convection in multi-scale climate models. By allowing the NN to say IDK sometimes and use the (expensive) cloud-resolving model (super-parameterized) solution just in those instances. Could this be another unexplored path that might achieve the dream of reliable prognostic stability?
Elizabeth Barnes
Mike – this is a really interesting idea. I could see that working, In addition though, I would imagine there are already networks out there designed to allow “exit ramps” while predicting that lead to more complex models?